CPU: noisy neighbor
What happens when one workload takes up too much CPU in a Kubernetes cluster? Let’s run a CPU-intensive job and see how it impacts our services.
Deploying the CPU Stress Job
The following Kubernetes job will create a single instance that consumes CPU resources:
apiVersion: batch/v1
kind: Job
metadata:
name: cpu-stress
spec:
template:
metadata:
labels:
app: cpu-stress
spec:
containers:
- name: stress-ng
image: debian:bullseye-slim
resources:
requests:
cpu: "1"
command:
- "/bin/sh"
- "-c"
- |
apt-get update && \
apt-get install -y stress-ng && \
stress-ng --cpu 4 --timeout 100s
restartPolicy: Never
Apply the Job:
kubectl apply -f cpu-stress.yaml
Now, let’s check the effects on our apps:
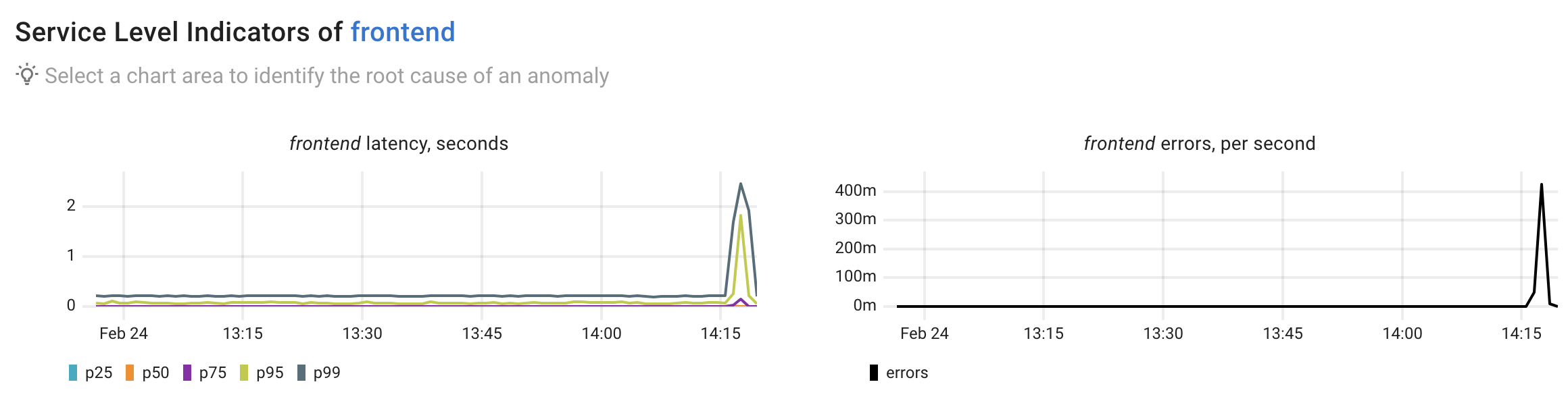
We observe clear anomalies in the frontend's latency and error rates. Next, let’s use Coroot to perform root cause analysis and explain these anomalies.
Root Cause Analysis
Here’s a summary of the AI-powered root cause analysis performed by Coroot Enterprise Edition (preview version).

Anomaly summary
The frontend service is experiencing increased latency (up to 131ms median, 2.17s p95) and failed requests (up to 0.57 per second). The service's performance degradation is primarily manifested through elevated response times and connection issues.
Issue propagation paths
The issue propagates through the following path:
- frontend → catalog → odb-postgres
- frontend → order → catalog → odb-postgres
Key findings and Root Cause Analysis
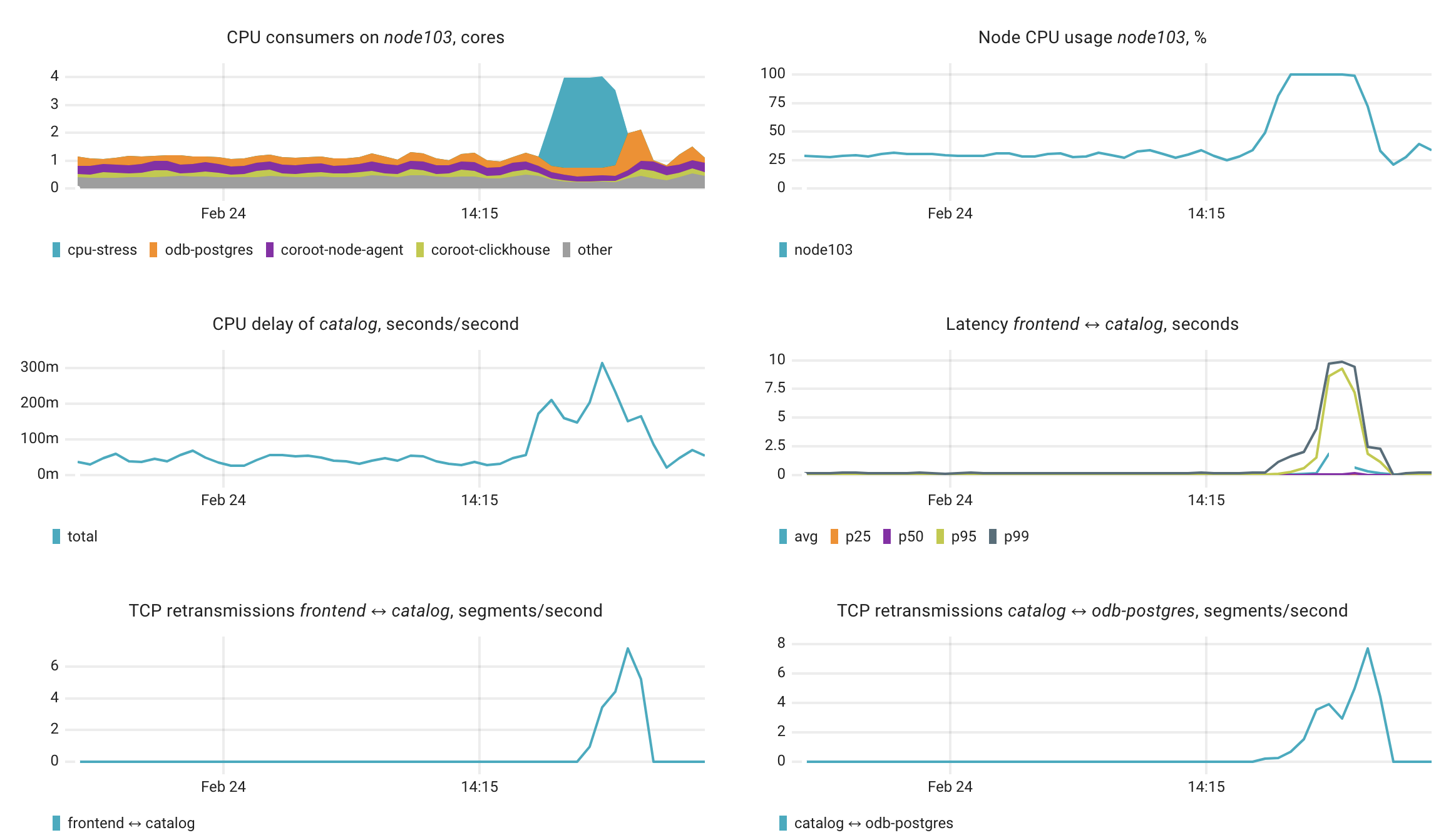
The root cause appears to be high CPU utilization on node103, which is affecting multiple services:
- The node's CPU is reaching 100% utilization
- A cpu-stress application is consuming significant CPU resources (up to 3.27 CPU cores)
- This is causing CPU delays in both catalog and odb-postgres services
- Network issues are present between services, with TCP retransmissions occurring between frontend-catalog and catalog-odb-postgres
- Multiple connection timeouts and refused connections are observed in the logs
Remediation
- Immediately investigate and terminate the cpu-stress application if it's not supposed to be running
- Consider moving catalog and odb-postgres to different nodes to distribute the load
- Implement CPU limits for applications running on node103
- Review network policies and ensure proper resource allocation for critical services
Relevant charts
How it works
Coroot's Root Cause Analysis (RCA) is performed in two steps:
- Analyzing the Model of the System: Coroot starts with the affected app, examining its metrics and logs to identify patterns linked to the anomaly. It then explores dependencies - services, databases, and infrastructure, tracing the issue through the system to pinpoint the root cause.
- Summarizing the Findings: Once Coroot gathers all the details, it sends the context to an LLM, which generates a clear summary and highlights the most important charts for faster troubleshooting.
Here’s a detailed RCA report showing how Coroot analyzed this anomaly. It might look complex, but it’s useful as evidence, making it easy to cross-check the relevant anomalies.

Notes on CPU Scheduling in Linux and Kubernetes
CPU scheduling in Linux is managed by the Completely Fair Scheduler (CFS), which distributes CPU time among processes based on priority and fairness. In a Kubernetes cluster, this determines how containers share CPU on a node.
Kubernetes interacts with Linux scheduling through CPU requests and limits:
- CPU Requests affect process weight in CFS, giving higher-requested pods more CPU time.
- CPU Limits set a hard cap, causing throttling if exceeded.
- Without CPU limits, processes can use extra CPU if available, but lower-priority workloads may suffer.
In our case, we set a high CPU request for the cpu-stress app, which gave it priority over other workloads, leading to performance degradation in our applications. Try running the same job without a CPU request, and you'll see that it has no impact on application performance.
Conclusion
This experiment shows how a single CPU-intensive workload can disrupt service performance, causing higher latency and errors. Because the cpu-stress app had a high CPU request, it took priority over other workloads, leading to resource contention and slowdowns.
With Coroot’s AI-powered root cause analysis, we quickly identified the issue, traced its impact, and found ways to fix it. This highlights the importance of setting the right CPU requests and limits, keeping an eye on resource usage, and catching issues early to keep your system running smoothly.